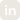As generative AI (GenAI) systems evolve from experimental tools to enterprise-grade applications, the balance between performance, cost, and safety has become a defining engineering challenge. Traditional approaches often treat these as separate priorities—optimize for speed first, then layer on safety—but the growing complexity of guardrails has made this trade-off unsustainable. Enterprises now need a new equation that integrates these three dimensions holistically rather than sequentially.
Every safety mechanism—whether a content moderation filter, hallucination detector, or policy compliance classifier—adds friction. Lightweight, rule-based filters might introduce mere milliseconds of delay, but sophisticated LLM-based checks can multiply response times by factors of five or ten. In high-volume enterprise environments, where latency directly affects user experience and throughput, this accumulation of micro-delays becomes a critical performance bottleneck.
What makes this especially urgent is that enterprises can no longer afford to compromise on safety for speed—or vice versa. Regulatory compliance, data privacy, and brand integrity depend on reliable guardrails. Yet users expect AI systems to respond instantly, like a human in conversation. This tension demands a new design paradigm: one where safety and speed co-exist through smart orchestration.
At Bud, our Guardrails team is actively tackling the challenge of balancing safety with real-time performance. We’ve launched a focused research initiative to explore just how far we can minimize guardrail-induced latency without compromising on safety or accuracy. Early results have been remarkable — our guardrail systems can bring the added latency from safety checks down to nearly zero, enabling seamless, instant AI responses even under stringent compliance and moderation layers. This breakthrough marks a major step toward achieving truly low-latency, enterprise-grade safety in generative AI.
In this article, we examine the key challenges with current guardrail systems, how various guardrails affect end-to-end latency, drawing on industry benchmarks and studies. We also highlight best practices to balance robust safety with real-time performance needs. In the upcoming articles in this series, we’ll discuss how the Bud Guardrail system brings down the Guardrail induced latency to near zero. We’ll be sharing detailed insights, methodologies, and benchmarks, stay tuned!
The Problems with Today’s Guardrail Systems
Despite the impressive progress in AI safety tooling, today’s state-of-the-art guardrail systems are not yet ready for enterprise production-scale generative AI applications. Beneath the benchmarks lie a series of fundamental limitations — from scalability issues to high infrastructure costs and fragmented coverage.
Problem #1: Current Guardrails and Good on Paper, Not in Production
Many of the leading guardrail systems — such as Meta’s PromptGuard, ProtectAI’s Detector, and similar open-source frameworks boast impressive numbers on paper. They often report sub-100 millisecond latency and “state-of-the-art” accuracy for classification tasks like jailbreak detection or toxicity filtering.
However, these reported benchmarks are typically based on limited input context lengths, usually around 512 tokens. In real-world enterprise environments, GenAI applications regularly process 4K to 8K tokens or more. That’s a 16X increase in input size compared to benchmark conditions. This creates a serious scalability gap:
- Guardrail models with 512-token limits can’t handle long-form inputs natively.
- To work around this, systems must chunk the input into smaller pieces and perform recursive evaluations, multiplying both latency and inference cost.
- Some systems instead trim input text to fit the 512-token limit — a shortcut that leads to context loss and false negatives, especially when unsafe content appears later in the input.
In short, the latency and accuracy figures that look great in papers fall apart when faced with production-scale workloads and real-time SLO (Service Level Objective) requirements.
The table below shows the performance results of Meta’s PromptGuard Guardrail. The experiments are run on A100 GPU, with model input size of 512 tokens. Even though the framework delivered sub 100 ms latency, on higher input size of 4k or 8K, this latency could sum up to several seconds.
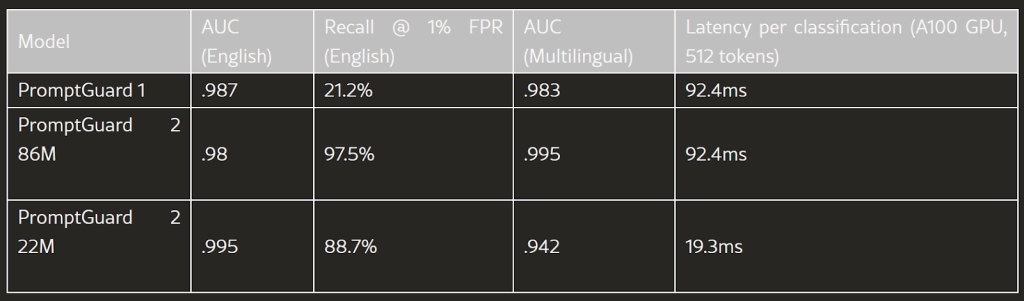
The graph below compares the performance of some of the SOTA guardrail systems against attack rates. PromptGuard 2 86M leads the chart with as low as 3.3% attack success rate. However, again, the model with input length of 512 tokens would perform well in the orchestrated benchmark conditions, but not sufficient for enterprise production ready deployment scenarios that deals with higher input context lengths and concurrent request.
Problem #2: Guardrails Eat Your Infrastructure Budget
Guardrails are designed to protect, but they come at a price. To maintain low latency and meet concurrency requirements, current guardrail systems must often run on dedicated GPUs. That means two separate high-performance infrastructures. One for the core LLM and another for the guardrail system itself. Even though guardrails don’t require the same compute intensity as large models, they still demand GPU-class resources to stay under 100ms response time.
GPU-based deployments significantly raise operational costs — sometimes consuming 25–50% of the total LLM infrastructure budget just to keep guardrails running. And to bring the Guardrail induced latency to the minimal level, the guardrail infra costs could match or go even higher than the application’s LLM deployment.
While it might seem tempting to shift guardrail workloads to CPU infrastructure to save costs, in practice this approach quickly breaks down.With current guardrails, CPU-based deployments cannot sustain production-level concurrency or response times, making them impractical for real-time AI applications despite the apparent cost advantage.
The result? Teams are forced to compromise — either paying heavily for application safety or settling for slow, less secure systems.
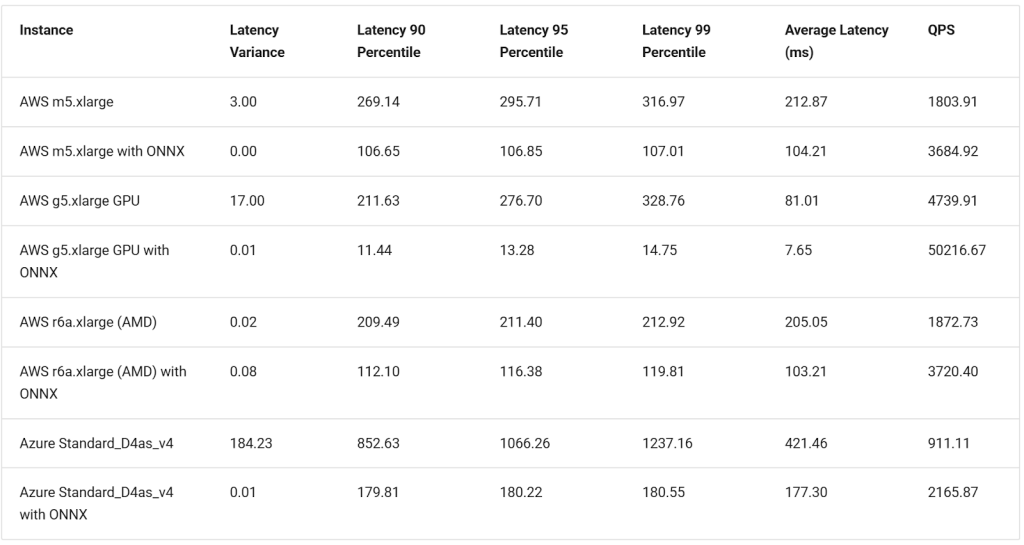
The table above shows the performance of ProtectAI’s guardrail system for prompt injection detection. As infrastructure becomes more powerful (CPU → GPU), latency consistently decreases — and ONNX further amplifies this advantage, making high-spec GPUs the fastest and most efficient option, but it results in high infrastructure costs as well.
Problem #3: No Unified Framework for All Risks
While SOTA guardrail models like PromptGuard, and ProtectAI’s Detectors achieve strong results in specific domains (for example, jailbreak detection or prompt injection filtering), none of them offer comprehensive coverage across the full safety spectrum. Each model or framework tends to specialize:
- Some are trained for jailbreak or prompt injection detection
- Others focus on toxicity, hate speech, or profanity
- A few handle code safety or PII leakage
This fragmentation forces developers to stitch together multiple guardrail systems or rely on plugin-based architectures, which increase technical complexity, latency, and cost.
The More Guardrails, The More Latency
Each safeguard, whether it’s a content filter, hallucination detector, or human review, introduces trade-offs in speed, cost, and flexibility. Simple rule-based filters may add only milliseconds of delay, while advanced LLM-powered checks or human moderation can stretch response times to seconds or even minutes. As enterprises layer multiple safety mechanisms together, these small costs can compound, impacting user experience and scalability. Understanding where and how guardrails add friction is key to balancing safety with performance.
Content Moderation Filters
These guardrails check user inputs or AI outputs for disallowed content (e.g. hate speech, violence, self-harm). They are often implemented via rule-based filters or ML classifiers (e.g. OpenAI’s Moderation API, Azure Content Safety). For example, OpenAI’s moderation models flag categories like hate, harassment, sexual or violent content. Content filters act as a bouncer, blocking or altering prompts/responses that violate policies. This is critical in enterprise use cases to enforce compliance and prevent toxic or sensitive data leaks.
For Content Moderation Filters, simple moderation filters tend to be fast. Rule-based keyword filters operate near-instantly. Classifier-based filters (using a small ML model or API) add a modest delay, often on the order of tens of milliseconds per request. A recent study found that open-source or API-based content classifiers can run in under 0.1 seconds per input. For example, lightweight models like iad-v3 or vijil (designed for prompt safety) achieve sub-100ms latency by trading off some accuracy. In practice, OpenAI’s moderation endpoint also returns results in a small fraction of a second in most cases (e.g. batched calls showed only a few milliseconds difference between models).
However, using a large LLM as a moderator (i.e. prompting GPT-4 or similar to decide if content is allowed) incurs substantially higher latency. Such LLM-powered guardrails were measured to be 5–10X slower than classifier-based approaches. In one benchmark, chain-of-thought (CoT) reasoning with a powerful model to judge content pushed moderation time up to 8.6 seconds. Another evaluation noted fine-tuned LLM moderators (like Claude with detailed reasoning) achieving nearly perfect safety recall but at 7 to 8+ seconds per response – clearly unsuitable for real-time use. In summary, content guardrails using small specialized models add negligible latency, whereas using an LLM itself as the filter can add seconds of delay. For interactive enterprise applications, the latter is generally too slow unless optimized.
Hallucination Detection
Hallucinations are plausible-sounding but incorrect outputs. Guardrails here aim to verify the AI’s responses against trusted data. Techniques include Retrieval-Augmented Generation (RAG) – feeding the model relevant documents to ground its answers – and post-generation fact-checkers. Some platforms (e.g. Amazon Bedrock Guardrails) offer grounding checks that run after the model generates a response, detecting if assertions lack support. If a hallucination is detected (e.g. via a knowledge-base lookup or an automatic correctness score), the system may refuse the answer, correct it, or escalate to a human agent.
Ensuring factual correctness often requires additional steps that can noticeably increase latency. A common strategy, RAG (retrieval-augmented generation), adds a retrieval step (database or search query) before generation; this retrieval might take anywhere from a few milliseconds (for an in-memory or vector DB lookup) to a few hundred milliseconds if calling an external search API. RAG also increases prompt length by injecting documents, which can slow the model’s generation slightly. Post-generation fact-checking introduces further overhead: for example, sending a completed answer to a secondary model or function that scores its factual accuracy. If the system uses an agentic workflow (an LLM dynamically orchestrating tools to verify answers), the latency compounds. Amazon has noted that using their Bedrock Agents (which let an LLM plan multi-step checks and call APIs) “can increase overall latency” compared to a static one-pass flow. The trade-off is improved flexibility and correctness versus speed.
In concrete terms, a hallucination guardrail might double the response time: e.g. a model that normally responds in 1 second might take 2 seconds if it first queries a knowledge base and then verifies the answer. More intensive approaches (like cross-checking every fact via web search or running multiple LLM votes for self-consistency) can multiply latency even further. Human-in-loop escalation for hallucinations (if the system decides it cannot answer confidently and defers to a human) introduces the most extreme delay – a human might take many seconds or minutes to respond, effectively halting the session. Thus, factuality guardrails must be designed to minimize interventions; enterprises often configure a confidence threshold under which the AI provides a safe fallback or asks the user to rephrase rather than always invoking a slow check.
Safety Classifiers and Policy Compliance
These are automated classifiers ensuring the AI’s output adheres to broader safety and usage policies beyond simple content filters. For instance, a safety layer might detect prompt injection attacks or confidential data in output. Security guardrails like prompt-injection detectors and PII scrubbing fall in this category. They often use ML models (e.g. BERT or smaller LMs) to classify responses as safe/unsafe, or to identify policy violations that content filters might miss (such as subtle defamation or compliance issues).
Many safety checks (e.g. toxicity or compliance classifiers) operate similarly to content moderation filters in terms of architecture. If using a small classifier model (such as BERT or DistilBERT fine-tuned to detect policy violations), each additional classifier might add ~10–50ms latency. For example, one report describes a two-step LLM classifier gate that adds an extra inference call to the pipeline. This is a “moderate latency overhead” in exchange for more nuanced safety decisions. Running multiple classifiers (to score toxicity, hate, sexual content, etc.) in sequence would sum these delays (e.g. four classifiers at 50ms each ~= 200ms added). To mitigate this, such classifiers can often be run in parallel threads, so total overhead is closer to the slowest single classifier rather than additive. Indeed, industry practitioners recommend sending every model output through parallel safety checks and aiming to keep the combined post-processing under about 50 milliseconds. With parallelization and efficient models, the latency impact of safety classifiers can be kept small enough for real-time use. (For comparison, using the generative model itself to judge safety would be slower – one paper noted that GPT-based moderation takes “a few seconds” per item, which is much more than legacy ML moderators that were tuned for speed.)
Bias Mitigation Mechanisms
To prevent discriminatory or biased outputs, enterprise systems may include bias detectors or adjust model prompts. This can involve pre-screening prompts for biased framing or post-processing model outputs to remove or rephrase biased content. Tools like fairness metrics (e.g. Fairlearn) can monitor bias. In practice, many bias mitigations are handled during model training or fine-tuning, but runtime guardrails (like scanning outputs for certain slurs or ensuring gender-neutral language) are also used. These often run as lightweight text analyses or additional model prompts that attempt to “debias” the response.
Guardrails to reduce biased or toxic language typically involve minor additional processing. Some implementations simply insert extra instructions into the prompt (e.g. “avoid stereotypes” or “use neutral language”) – this increases the prompt token count and hence the model’s workload slightly. Large prompt-based policies can degrade performance if overused; one analysis found that enumerating many guardrail instructions (hundreds of tokens) in the prompt can significantly increase token processing and thus cost and latency.
For example, clearly defining a dozen complex policies in every request might require 200–300 extra tokens, slowing generation and raising inference cost by multiples. A more efficient approach is to use a lightweight bias checker on the output: e.g. a regex or small model that flags certain biased terms. Such a check is very fast (a few milliseconds). If a bias is flagged and a mitigation is applied (like regenerating part of the response or applying a transformation), that could add another model call or processing step. In general, bias mitigation guardrails either negligibly impact latency (if just passive monitoring or slight prompt tweaks) or introduce a small delay if they actively intervene (since they might trigger a partial redo of the output). As with other guardrails, the key is to avoid complex, sequential processing. Enterprises often bake bias reduction into the model via fine-tuning or use prompt techniques that don’t require multiple back-and-forth steps, thereby avoiding latency penalties at runtime.
Human-in-the-Loop Moderation
For high-stakes applications, humans may review certain AI outputs flagged by the automated guardrails. A human moderator can make final decisions on borderline cases or override the AI. This is used sparingly due to cost and speed, but it provides a safety net for ambiguous or critical content. For example, a system might automatically escalate a potentially harmful response to a human reviewer instead of immediately delivering it to the user. Human oversight is crucial for content that AI finds uncertain (e.g. nuanced hate speech), though it cannot scale to every request in real-time.
Introducing human moderators into an AI workflow is inherently slow relative to machine speeds. A human reviewer typically takes on the order of tens of seconds to evaluate a single piece of content. (Studies of content moderation note that human moderators spend ~10–30 seconds per item on average.) While AI guardrails are faster than humans, relying on a person for in-line approval will break any real-time interaction. Therefore, human-in-the-loop is usually reserved for either offline review (after the AI has responded, for auditing purposes) or for very high-risk queries where the session can be paused. If a workflow escalates a response to a human before replying, users may wait minutes – unacceptable for most applications. Because of this, human oversight in enterprise GenAI is often implemented as human-on-the-loop rather than gating each response: the AI might respond immediately but log the exchange for later human review, or a human moderator might review and override certain AI outputs in near-real-time on a dashboard, rather than pausing every response. In summary, the latency impact of human guardrails is orders of magnitude larger than automated checks, so they must be applied sparingly and strategically.
Other Guardrails: Depending on the enterprise context, additional guardrails can include format validation (ensuring the AI output conforms to required schemas), robustness checks (handling adversarial or malformed inputs), and compliance logging (auditing all AI interactions). Each layer could add to the end to end latency of the application.
Benchmark Results and Case Studies on Guardrail Overheads
Both academic research and industry case studies highlight the trade-offs between guardrail thoroughness and system speed:
- “No Free Lunch” Study: A comprehensive benchmark of content moderation guardrails (open-source vs. API vs. LLM-based) quantified the latency overhead of each. The findings showed small classifier-based guardrails operate in the tens of milliseconds range, whereas more sophisticated LLM evaluators incur multi-second delays. For example, a simple BERT-classifier or an API like Azure’s content filter could evaluate a prompt in ~0.05 seconds, while an LLM reasoning-based moderator took 5–10X longer, reaching 7 to 8.6 seconds latency on the same tasks. The study also noted a specific open-source safety model (Claude-3.5 with reasoning) achieved top adversarial detection scores at 7.88s latency, underscoring the trade-off between robustness and speed. Conversely, a lean model (vijil-mbert) could perform a targeted prompt-injection detection in under 0.1s but with lower coverage. These results confirm a key point: stronger guardrails often mean slower responses, and finding the balance is critical.
- Static vs. Dynamic Guardrails: It observed that a deterministic rule engine (e.g. “LlamaFirewall”) adds virtually no latency but is brittle, whereas an LLM-based classifier gate is more flexible but “adds an inference latency” due to the extra model call. This latency was characterized as moderate, acceptable in many cases but noticeable compared to the instant rule check. NVIDIA’s NeMo Guardrails (a programmable runtime with dialogue management) offers powerful control but with some overhead due to its complexity – it essentially runs a dialogue policy engine alongside the model. NVIDIA’s own research highlighted that enabling robust guardrails can triple the latency of a standard LLM service if done naively. This “triple latency” often comes from sequential prompt processing or multiple model calls. It reinforces that piling on guardrails without optimization can heavily degrade throughput.
- OpenAI Moderation API Experience: Developers using OpenAI’s free moderation API have generally found it fast, but there are reports of occasional slow responses (e.g. spikes up to a few seconds). In normal operation, the moderation call is quick enough that OpenAI suggests it can be done in parallel with the generation call to hide any added wait. By doing so (sending the prompt to the moderation endpoint and the main model simultaneously), one can often get the moderation result without extra user-perceived latency. The only latency cost then is if the moderation flags something – in which case the main model’s work is wasted or a placeholder must be returned. This design pattern (async moderation) is a direct result of needing to eliminate serial latency in the user experience.
- LLM vs Traditional Moderators: A 2024 study on using GPT-4 for content moderation noted that LLM moderation, while more accurate, is slower than older ML systems. It reported that GPT-based moderation could take “a few seconds” per item, whereas legacy models or heuristic filters operate much faster. Thus, in high-volume scenarios (e.g. social media), pure LLM moderation for every piece of content may bottleneck throughput. The conclusion was that LLMs should augment, not replace, fast traditional filters for the easy cases – for instance, use LLM moderation on the tougher, context-dependent cases (which are fewer), while allowing simpler AI or even human moderators to handle straightforward content more quickly. This tiered approach preserves efficiency by not applying the slowest method universally.
- Agent Orchestration Case: The Amazon Bedrock Agents example demonstrates a case study of orchestrating guardrails. By letting an LLM agent dynamically decide when to call a tool or human, they gained flexibility in handling hallucinations but explicitly call out increased latency as a cost. In their workflow, if a generated answer’s confidence score was low (possible hallucination), the agent would invoke a human notification instead of responding. This obviously introduces a significant delay for that query, but since it’s only for the low-confidence cases, the overall user experience is preserved for most answers. It’s a form of graceful degradation: most answers are fast, and only the uncertain ones slow down (with a clear reason). The key takeaway is that case-by-case guardrail invocation can control latency impact – not every response needs the full gauntlet of checks, especially if it’s likely fine.
In summary, empirical evidence across studies and implementations shows that guardrails can introduce anything from negligible latency (a few milliseconds) to very large overhead (multiple seconds), depending on how they’re implemented.
Stronger safety and accuracy often come at the cost of speed and user experience.
Best Practices for Low-Latency Guardrails
Achieving both safety and speed requires careful architecture and tuning of guardrails. Here are best practices for balancing guardrail effectiveness with real-time performance in enterprise GenAI deployments:
- Parallelize and Pipeline Checks: Wherever possible, do not run guardrail checks sequentially after the main model call. Instead, run them in parallel or interleaved. For example, a common design is to launch the content moderation check asynchronously alongside the generation request. If the generation finishes and the moderation has not flagged anything, you can return the answer immediately; if the mod flags content, you can halt or replace the output in that moment. Similarly, multiple post-generation classifiers (toxicity, compliance, etc.) should be executed concurrently on the output text. This event-driven approach keeps the main thread flowing and avoids making the user wait on back-to-back checks. Enterprises have likened this to a zero-trust pipeline where every response is checked in parallel “with every token considered guilty until proven innocent,” yet done so efficiently so that overall response time remains snappy.
- Use Lightweight Models and Heuristics First: Not every guardrail needs a giant model. Implement a tiered guardrail strategy: use fast, lightweight filters to catch obvious issues, and reserve heavier, slower checks for the trickiest cases. For instance, simple regex or keyword filters can instantly reject inputs containing certain slurs or disallowed phrases (zero latency). A small “fast classifier” can handle the majority of content filtering under 50–100ms. Only if these light checks are inconclusive or if the context is very complex should a system fall back to an LLM-based evaluation. This design is akin to a triage: the guardrail acts as a cascade of increasing scrutiny. By handling the bulk of traffic with efficient rules/models, you ensure most requests see minimal delay, and you invoke the slow, meticulous guardrails only when absolutely necessary.
- Minimize Prompt Bloat: Avoid the temptation to pack exhaustive policy text or lengthy instructions into every model prompt. While prompt-based guardrails (in-context instructions) can steer the model, they come at a cost: more tokens to process = higher latency. In one scenario, adding a 250-token policy paragraph to each request increased both cost and latency significantly. A best practice is to keep system prompts concise and offload detailed policy enforcement to side-channel checks (like the moderation API or classifiers). If you must inject policies via prompt, consider dynamic prompt injection where only relevant rules (for the domain or context of that query) are inserted, rather than a monolithic policy. The goal is to avoid “overloading” the model’s input, which not only slows inference but can even degrade the model’s performance if too many constraints are given.
- Caching and Reuse: In some enterprise applications, users may repeat queries or certain safe responses occur frequently. Caching the outputs of guardrail checks can save time. For example, if your toxicity classifier has already seen a particular response (or a very similar one) and deemed it safe, you might skip running it again and reuse the result (assuming context hasn’t changed). Moreover, common safe outputs (like generic greetings or disclaimers) can be whitelisted to bypass heavy checks. Caching is tricky for generative AI since every response is unique, but partial reuse (such as not re-checking the same user prompt twice in a session) can shave off milliseconds and is worth considering under high load.
- Set Smart Thresholds and Tune Frequency: Balance how aggressively guardrails intervene. A very strict guardrail that flags borderline content will send many items down slower paths (or to humans), hurting latency for little gain. It might be better to set a threshold where the guardrail only triggers on high-confidence issues. For example, a factuality checker might only escalate if it’s highly sure the answer is wrong – allowing slightly suspect answers to preserve latency for the user, while logging them for later review. This kind of risk-based thresholding ensures guardrails don’t over-fire and unnecessarily slow the system. It requires tuning based on the enterprise’s tolerance: e.g. a medical advice bot will have low tolerance for error (and accept more latency), whereas a casual chatbot might tolerate some minor inaccuracies to stay realtime.
- Gradual Rollout and Shadow Testing: Introducing guardrails should be done gradually to observe latency impact. One best practice is to deploy new guardrails in shadow mode first – the guardrail runs and logs its decisions but does not block or alter outputs yet. This allows measuring how often it would trigger and how much latency it would add. With that data, you can adjust the guardrail or improve its performance before it goes live. When enabled, use feature flags or A/B tests to ensure that if it severely impacts latency or user experience, you can quickly disable or tweak it. This iterative approach prevents a well-intentioned safety feature from unexpectedly grinding your system to a halt.
- Human Oversight Off the Critical Path: Wherever possible, keep human review out of the immediate response loop. Humans can be involved in reviewing a sample of outputs, handling user appeals of AI decisions, or labeling data to improve models – all important for safety – but these should be parallel or post hoc processes. If a human must be part of the real-time pipeline (e.g. final approval in a high-stakes scenario), be transparent with users that responses will be delayed, and perhaps only apply this for a tiny subset of interactions (like transactions above a certain dollar amount, in a fintech application). In most cases, a better design is human-on-the-loop: the AI responds instantly under automated guardrails, and a human later reviews logs or is alerted to any incidents. This maintains a good user experience while still providing a human backstop for safety.
- Monitoring and Optimization: Treat guardrails as part of your performance monitoring. Track the latency introduced by each guardrail component (e.g. log how long the content filter took, how often it delayed responses). If a particular safety layer becomes a bottleneck, optimize it: this could mean upgrading a model to a faster version, moving a service closer to reduce network latency, or simplifying a rule set. Monitoring also helps catch when guardrails fail open or fail closed (either letting bad content through or flagging too much). Automated alerts can watch metrics like overall response time or queue length and notify if guardrails are causing SLA breaches. In one case, a company discovered their prompt-injection detector started taking too long under heavy load; the fix was to batch queries to it and thereby cut per-item latency. Continuous performance testing of the guardrail pipeline under realistic conditions is key to balancing safety/performance.
Conclusion
Adding guardrails to GenAI deployments is not optional in enterprises – it’s essential for safety, compliance, and trust. However, every guardrail introduces a trade-off. Well-designed guardrails need not sink performance. With a thoughtful architecture, enterprise GenAI deployments can remain both safe and responsive. The best implementations of guardrails are almost invisible to the end-user – they work behind the scenes in milliseconds, until the rare moment they must intervene.
In the upcoming articles in this series, we’ll discuss how the Bud Guardrail system brings down the Guardrail induced latency to near zero. We’ll be sharing detailed insights, methodologies, and benchmarks, stay tuned!







.png)